Logistic Regression
Logistic regression algorithm finds a linear function that predict class () given an input vector as,
\begin{equation} \hat{y}=\sum_{n_x}^{j=0} w_jx_j+b=w^Tx+b \end{equation}
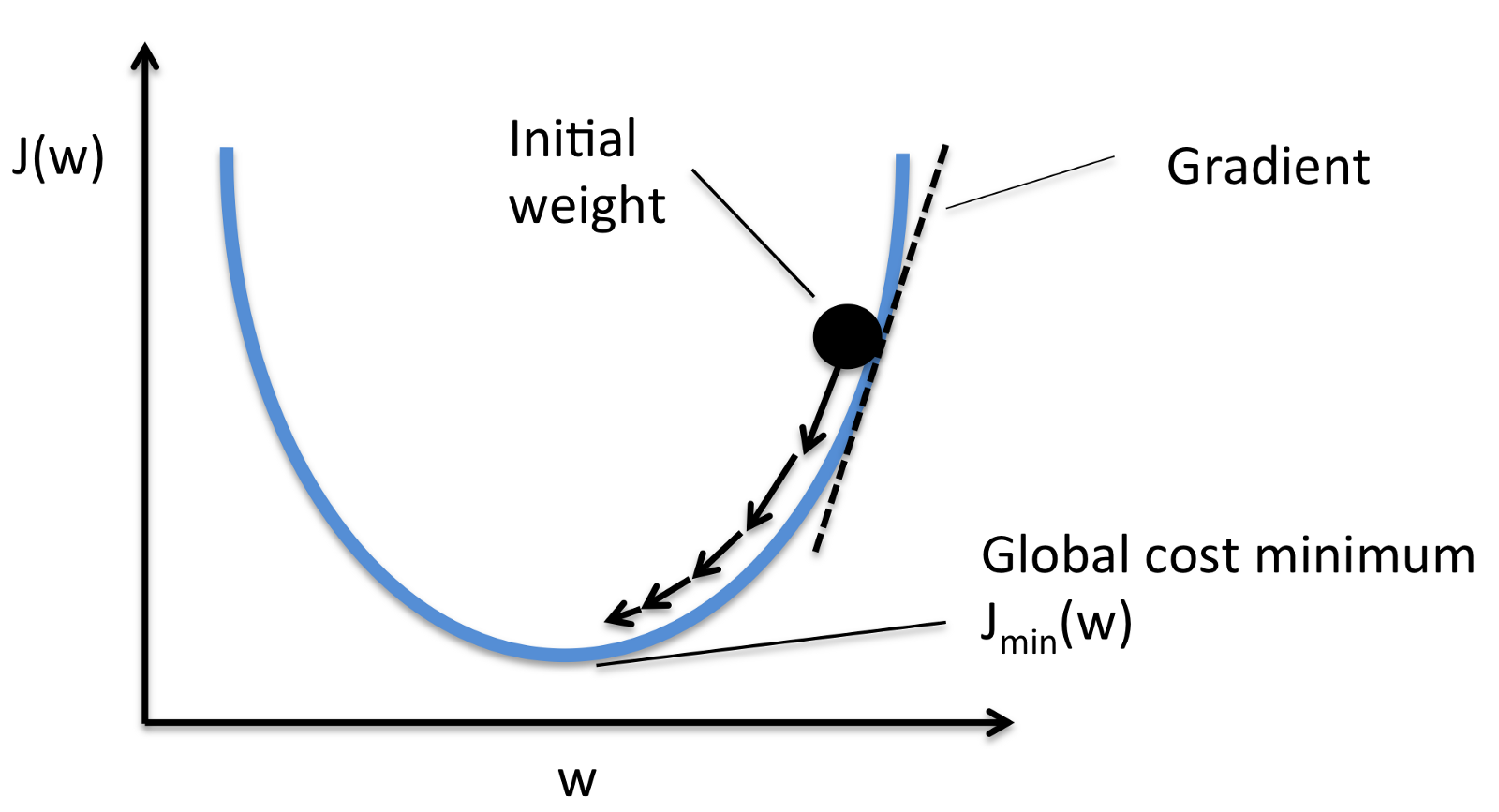
The final goal here is to find optimal weights that best approximate the output y by minimizing the prediction error. The simple loss function or error function is one half of square error as, \begin{equation} L(\hat{y},y)=\dfrac{1}{2}(\hat{y}-y)^2\approx 0 \end{equation}
Typicaly, the output should be in probability form (), and thefore sigmoid function ( or similar function) is applied to predicted output. So that the final Logistic regression can be shown by, \begin{equation} \hat{y}=P(y=1|x) \longrightarrow \hat{y}=\sigma(w^Tx+b) \end{equation}
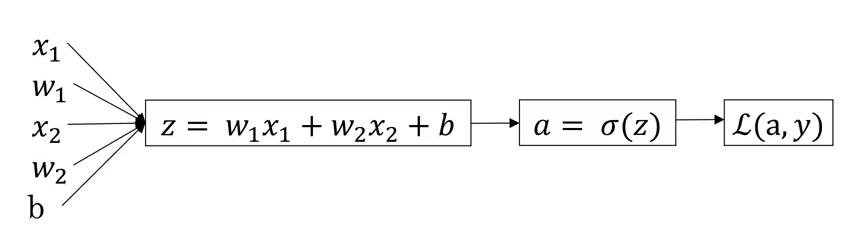
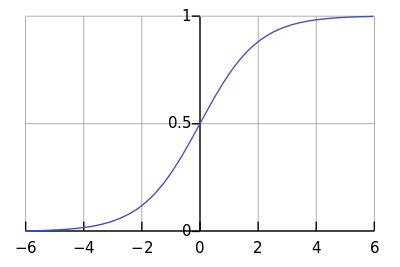
The sigmoid function, , gives an shaped curve as shown in Figure 1. when and when . The when . Therfore, If the output is more than $ 0.5 $, the outcome can be classify as 1 and 0 otherwise.
The half a square error might cause the optimization problem (non-convex problem). To prevent multiple local optima the loss function can be written as,
\begin{equation} L(\hat{y},y)=-\big(y\log \hat{y}+(1-y)\log(1-\hat{y}) \big) \label{eq:loss} \end{equation}
Above equation measures how well th model is for one a single training example. The overall performance over training is indicated by cost function $ J $ as,
\begin{equation}
J(w,b)=\dfrac{1}{m} \sum_{i=1}^{m} L(\hat{y}^i,y^i)
\label{eq:cost}
\end{equation}